I’ve been writing up my PhD. This has been a very slow process, mainly because I’ve had to spend quite a bit of time going back through all my references, and re-planning the whole thing. I bought post-it notes, and a tabletop flip chart (which is also like one massive post-it), and I’ve re-appraised everything. As I write, I’m constantly adding more post-its as prompts of things I need to look up / do / add to the ‘discussion’ section at the end.
One of the things I decided I’d do was go back through my original data to make sure that I’d gathered everything I needed to, and to see if I could improve the cleaning-up process. In computer science circles, this is often referred to as ‘text wrangling’. Your typical blog post contains URLs, other advertising rubbish that’s added by the platform, junky unicode, characters representing carriage returns, new lines…. I could go on. This all has to be removed. A text data file, when its being prepared for analysis, can get very big very quickly – and there’s a limit to the data file that even my pretty-well-spec’d laptop can handle. Having discovered this excellent site, I can not copy and paste a section of a blog post with some rubbish in it, and generate the code snippet that will remove it. Regex can be tricky – the broader the parameters i.e. the greater freedom you give it to remove the stuff you don’t want, the more chance there is that it’ll remove other stuff you really would have preferred to keep. It’s difficult to check, though, so in the end you probably have to just take the risk.
The other thing I wanted to do was expand the contractions in the posts so that ‘isn’t’ becomes ‘is not’ etc. I think it’s important to leave behind a data set that may be useful to future researchers, some of whom might be interested in sentiment analysis. Expanding contractions helps to keep the meaning of the writing intact.
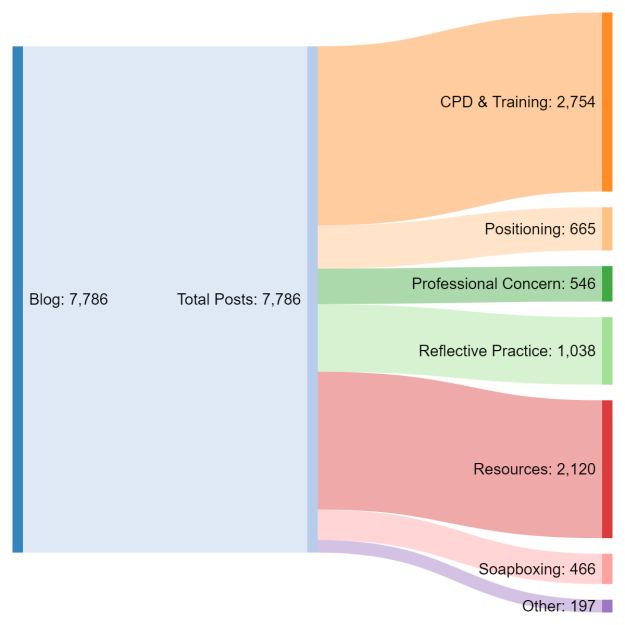
Then, I decided I’d go back and look again at how I’d processed my data. As you may recall, my aim is to classify as many edu-blogs as possible according to a pre-defined list of categories drawn from the research that’s already been done on what teachers blog about. I chose this approach because the potential number of topics is completely unknown, and potentially huge. It’s possible to run an algorithm that will cluster blogs without any prior information, but the trouble is that a) you still have to give it some idea how many clusters you might be expecting, and b) the results will vary slightly each time it’s run. Its not a model; there’s no consistency.
One of the alternatives is to label a small set of blog posts with numbers representing categories, and then use an algorithm that will take this information and classify the unlabelled posts. This is how it works: imagine having a double handful of brown smarties and a clear perspex box, say 1m x1m. You throw the smarties into the box, but by magic they remain stationery, but scattered, in space. Now you have a small number coloured smarties, several of the remaining colours, and you chuck them in as well. They also hang in space. The label spreading algorithm assumes that the coloured smarties are the labels, and it sets about relabelling all the brown smarties according to how close they are to each different colour. You can allow it to change the colours of the non-brown smarties if you want, and you can give it some freedom as to how far it can spread, say, the red colour. The algorithm spreads and re-spreads each colour (some of the different coloured smarties will be quite close to each other…. where should the boundary be drawn?) until it reaches convergence.
 The picture here (and above) is a great example. Not only does it look like a load of smarties (which I’m now craving btw) but it also perfectly illustrates one of the fundamental problems with this approach – if your data, when plotted into a 3D space, is an odd shape, spreading labels across it can be a bit of a problem. The algorithm draws a network (there are lines connecting the smarties if you look closely) and uses the links between the smarties – officially called ‘nodes’, links are ‘edges’ – to determine how many ‘hops’ (edges) it takes to get from your labelled node to your closest unlabelled one.
The picture here (and above) is a great example. Not only does it look like a load of smarties (which I’m now craving btw) but it also perfectly illustrates one of the fundamental problems with this approach – if your data, when plotted into a 3D space, is an odd shape, spreading labels across it can be a bit of a problem. The algorithm draws a network (there are lines connecting the smarties if you look closely) and uses the links between the smarties – officially called ‘nodes’, links are ‘edges’ – to determine how many ‘hops’ (edges) it takes to get from your labelled node to your closest unlabelled one.
Each of these nodes could represent a blog post. It has co-ordinates in this space. The co-ordinates are generated from the words contained in the post. The words have to be represented as numbers because none of the algorithms can deal with anything else – this is maths territory we’re in, after all.
I’ve one this label spreading thing before with a sample set of data. It seemed to work ok. A quick audit of the results was promising. I had another run through the code with a different set of data, including the training set I’d developed earlier, and realised that things weren’t quite the same. The algorithm has had a bit of an upgrade since I last deployed it. There were some issues, and the developers from scikit-Learn made some improvements. That got me re-thinking what I’d done, and I realised two things: I’d made a fundamental error, and the new results I was getting needed a bit of an audit.

The book on the right has been invaluable!
The fundamental error really shows up how hard it is to do data / computer science when you aren’t a data / computer scientist. I was feeding the algorithm the wrong set of data. I should have been feeding it an array of data based on distance, but I wasn’t. I was still getting results though, so I didn’t notice. The thing is, nowhere is there anything that says ‘if you want to do this, you must first do this because this’. It’s just assumed by every writer of computer science books and blogs and tutorials that you know. I went back and re-read a few things, and could see that the crucial bit of information was inferred. I can spot it now I’ve gained a lot more knowledge. So, fault corrected, move on, nothing to see here.
The audit of results isn’t very encouraging, though. There were many mis-categorisations, and some that were just a bit…. well… odd but understandable. One of my categories is ‘soapboxing’ – you know, having a bot of a rant about something. Another is ‘other’ to try and catch the posts that don’t fit anywhere else. Turns out of you have a rant in a blog post about something that isn’t about education, it still gets classed as ‘soapboxing’, which makes perfect sense when you think about it. An algorithm can’t distinguish between a post about education and a post that isn’t, because I’m thinking about concepts / ideas / more abstract topics for blog posts, and it’s just doing maths. Post x is closer to topic a than topic b, and so that’s where it belongs.
There are other approaches to this. I could use topic modelling to discover topics, but that has problems too. ‘People’ might be a valid topic, but is that useful when trying to understand what teachers have been blogging about?
My label spreading approach has been based on individual words in a blog post, but I could expand this to include commonly-occurring pairs or trios of words. Would this make a significant difference? It might. It would also put some strain on my laptop, and while this shouldn’t necessarily be a reason not to do something, it’s a legitimate consideration. And I have tried tweaking the parameters of the algorithm. It makes little difference. Overall, the results aren’t different from one another, which is actually a good thing. I can make a decision about what settings I think are best, and leave it at that. The problem, the real problem, is that I’m working with text data – with language – and that’s a problem still not solved by AI.
What I cannot do is make the data fit my outcome. Worst case scenario, I have a lot to add to the ‘discussion’ part of my PhD. If I can come up with a better analytical framework, I will. The hard work – harvesting and wrangling the data – has already been done. If I have to find some more papers to add to the literature review, that’s no hardship. In the meantime, I’ve slowed down again, but I’m learning so much more.